

文|秦章勇
如果站在上帝视角,去看过去一年自动驾驶的发展,会发现选手们走了很多“弯路”。
去年下半年,车企还在做“轻地图、重感知”的城市NOA落地方案,BEV+Transformer和OCC占用网络成为竞逐赛道,AI代驾、全国都能开也是营销热词。
到了今年,在特斯拉的带动下,端到端又成了技术圣杯。
技术路线一旦调整,就意味着公司组织架构必须跟着变。理想在过去一年做了三代技术研发,从NPN到无图方案,再到如今的端到端。

“虽然有切换的成本和组织管理上的代价,但对我们来说都是值得的。”理想汽车智能驾驶副总裁郎咸朋表示,这也是理想的优势,具备很强的组织效率和管理执行能力。
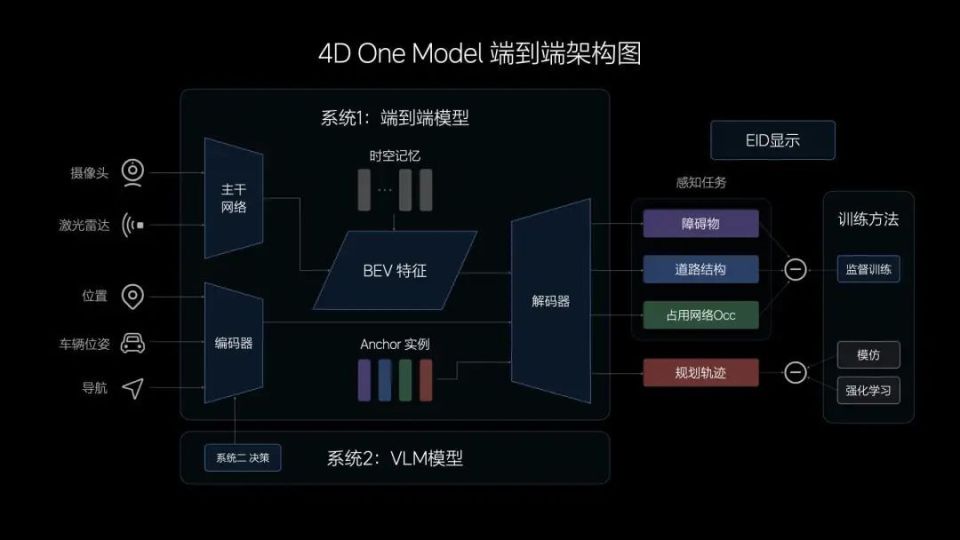
前不久,理想推出端到端(E2E)+视觉语言大模型(VLM)的技术架构,和分段式端到端方案不同,理想采用的是One Model方案,也就是说感知和决策模块都由一个模型完成,输入的是传感器数据,输出的直接是驾驶轨迹。
这让理想对数据和算力的要求提高到巨大量级,理想内部初步估算,现在每年投在训练上的费用是10亿人民币,未来还将上涨到10亿美元,这还不包括人员和其他的成本。
这种烧钱速度,无疑会把缺乏实力和魄力的选手排除在外,另一层意思就是,不是每家企业都能做好智能驾驶。
智驾对销量提升的效果也是立竿见影,自端到端推出一个月来,理想Max版本销量提升近20个点。时至今日,理想仍然按部就班发布“周销量”,自己一直稳坐在冠军位。
理想CEO李想曾为团队立下目标——2024年成为智驾绝对头部,从销量来看,理想的智能驾驶工作似乎得到了回报。
接下来理想对智能驾驶该如何规划?为什么理想能在短时间内做到这种程度?最近我们和理想智能驾驶副总裁郎咸朋、智能驾驶技术研发负责人贾鹏聊了聊。
以下是《超电实验室》及其它媒体和郎咸朋、贾鹏的对话节选。(有删改)
Q:理想的这条技术方案,未来会不会下放到无激光雷达版本?
A:之前大家之所以说不用激光雷达,主要因为成本太高,现在激光雷达的成本越来越低,新一代激光雷达可能只有1000来块钱,也就是两个摄像头的价格。
而且激光雷达就是一个传感器,最大的用处还是用在安全上,安全不仅仅说是给自动驾驶系统去用,而是在人开车的时候它也可以提供安全,比如像主动安全AEB等功能。
借用想哥(李想)一句话,我们想把激光雷达看作类似安全带或者安全气囊的配置,以后可能就是标配了。

Q:发布会上说有两套系统冗余,那么系统1和系统2是怎么分工的?
A:我们有两个模型,各有一颗Orin-X芯片,系统1的端到端模型,大概有3-4亿参数量,需要非常高频的去控制车辆,能跑到十几赫兹。
系统2的VLM模型很大,大概有22亿参数,其实也是一直在跑,我们把它优化到大概3-4赫兹,目前大概有三百毫秒的延迟,其实也是在每时每刻都在决策。
端到端模型除了传感器之外的数据,其中还有系统2的决策,所以为了达到L3/L4级别的自动驾驶,肯定还是系统1发挥主要作用,系统2只是一个参考类似于辅助的作用,关键时刻做一些辅助。
我们的理解是,真正到L4的时候,系统2会参与更多的决策,不是说系统2时时刻刻都在控车,而是要发挥非常重要的决策和判断作用。系统2的能力决定了能不能到L4,但系统1的技术能力是实现L3的必要保障。
Q:未来这两个系统有可能会合一吗?
A:目前还是受限于车端算力本身,Orin-X的算力并不大,当初我们只能说把两个模型给分开,但是随着Thor的到来,两个系统最终肯定会合成一个统一的模型。
而且兜底的策略,也有可能被VLM自己处理掉,因为VLM本身就有逻辑思维的能力。目前我们的团队正在做这件事,未来也会朝着这个方向走。
Q:研究过这么多新的智能驾驶方案和路线,如果未来有其他更好的范式,你们会不会跟进?判断这条技术路线的标准是什么?
A:很难有一个评判标准说这个方案很新或者很厉害。大家表面上看是我们不停在迭代,跟别人学也好还是自己探索也好,但实际上我们不是套路别人的公司,我们有自己的对技术和产品的本质上的理解。而且我们也不是为了端到端而做端到端的,从本质上看,无论是NPN还是重图,它最大的问题是只要用图就做不了全国。
如果不摒弃现在无图这套技术,不管是分散式的还是模块化的,总归还有人写的规则在里面,这样就永远做不到“拟人”化驾驶。
端到端则是可以按照人类的思维去做一些决策,虽然这里边有切换的成本,会有一些组织管理上的一些代价,但是我觉得对于我们做的事情都是值得的。当然这也是我们理想的一个优势,组织效率和管理执行能力很强。
Q:在面对老司机的 clips (视频片段)数据时,你们是记录所有片段,还是会筛选?
A:是需要筛选的。
因为我们有这个基数,所以说我们能筛出来高质量的1000万的片段,可能表面上看就只有1000万,但实际上它是从12亿公里的数据里边筛出来的。
我们筛选数据的时候,背后有一套我们自己的工具链,不是简单的挑一挑、剪一剪就好了,我们也有自己的一些配比和数据的配方,这也很关键。
因为投喂给大模型的数据首先要保证量大,第二是要保证质量要好,有时候马斯克的话还是非常对的,就是100万量级参数可以让模型开始工作,300万可以工作得比较好,达到1000万时,模型就能有很好的表现了,我们现在基本上做到300万的量级了。

Q:端到端发展到一定阶段后,理想在这条道路上的长远计划是什么?
A:从端到端开始,大家开始真正用人工智能的方式去做自动驾驶,我相信头部玩家一定会朝着这个方向去做的,一旦进入这个领域,大家的差距一定会被拉大。
真正到了人工智能时代,大家其实拼的是两件事,一个是你有没有足够多高质量的数据,第二是有没有与之相匹配的训练算力的集群,拼算力和拼数据这两件事的门槛非常高。
我们初步估算,理想每年投在训练上的花费是10亿人民币,未来我们预估每年要花费10亿美金,还不包括其他的人员及其他成本。
所以说,如果一年拿不出10亿美金来去做训练,可能会在将来的自动驾驶竞争中被淘汰。
Q:同一款车同样的配置,为什么在不同地区的智驾能力不同?
A:为什么小鹏的智驾在广州表现很好,华为在上海也是特别好?包括特斯拉也是在网红路线和西海岸线开的好,东海岸就比较差。
因为他们在这些地区的数据更丰富,理想一大优势在于增程车可以去很多地方,数据的区域分布和场景分布肯定高于纯电动车,数据的分布是足够广的。
做了一段时间端到端后,我们发现数据配比非常重要,我觉得一定要做到均衡,并不是说北京上海的用户多,数据就要加得的多,而是需要按照场景去均衡的配置。
有点类似炼丹的感觉,炼丹的配比怎么样才能保证在全国各地都能开得比较均衡,这是端到端时代大家面临的一个最大的挑战。
Q:现在都在讨论数据、算力和算法,你们对这三个维度是怎么排序的?
A:长远看,算力和数据都很重要,但是前期对人才的需求还是比较大,算法对应的其实也是人才,可能早期大家都觉得应该从去美国去请人工智能专家,但是最近这几年,其实中国的自己本土的人才也非常优秀,很多的人也从国外回来了。
今年七八月份,我们已经入职了240多个校招生,排名都是前100的大学,我觉得这是我们团队保持活力和保持技术的先进性的一个前提。

Q:一些平台型公司认为,原生多模态模型加入图像数据后,性能反而在下降,他们认为车企或者只做自动驾驶公司来说有非常深的壁垒,对此你们怎么看?
A:他们主要在通用人工智能领域研发,其实对垂域来说没有太大的借鉴意义。
这两边唯一相通的地方就是预训部分,就是把人类所有的文字语言的东西全部扔给模型。但是在后期怎么去训练,把它翻译成一个垂域的模型,怎么加入自动驾驶的知识,还不影响他的常识,这是他们没做过的,我们反而更有优势。
像动辄百亿千亿万亿的参数,是不可能完全交给汽车去处理的,没有硬件能扛得住。相比之下,云端可以有无限的算力,它门槛反而没那么高。
Q:所以说做自动驾驶端到端,要比做具身智能和人形机器人门槛会更高?
A:我觉得这俩是相通的。我们的这套方案,其实是受了Google的机器人系统 RT-1 和 RT-2的启发,其实我们认为这两个范式是一样的,自动驾驶本身就是个4轮机器人。
如果是你能拿VLA 或者VLM模型能做机器人的话,也当然可以做自动驾驶,但机器人有个好处,它实时性要求没那么高,不像车一样,必须得300毫秒或者200毫秒就得反应过来,机器人那个动作你可能不需要那么高的实时性。
这就可以把模型做得更大一点,但帧率低一点。但剩下的范式从数据驱动到到最后的验证,包括中间的VLM模型设计,这基本是相通的,只不过是你在车上还是具身在机器人上。

























