

文 | 王磊
编辑 | 秦章勇
昨晚,理想开了一场智能驾驶夏季发布会,与其说是发布会,更像一场理想汽车的AI Day。
复盘整场活动,技术干货满满,甚至有点过于干了。。
从推送“全国都能开”的无图NOA,再到后半场的基于端到端模型、VLM视觉语言模型和世界模型的全新自动驾驶技术架构。
或许因为纯技术类解读,李想本人并没有在发布会露面。看来自理想MEGA发布以来,李想越来越低调,但理想汽车的斗志却越来越强了。
理想拉齐“无图化”
这次的发布会,最重磅的莫过于理想的智能驾驶迎来拐点——无图NOA,并将在7月内全量推送。

这次升级虽然覆盖了理想MEGA和理想L9、理想L8、理想L7、理想L6全部车型,但仅限AD Max版本。
理想有两套独立智驾方案,分别是“AD PRO”和“AD MAX”,具体到车型也很好区分,理想L系列MAX版以上搭载都是”AD MAX“高阶智驾,具备城区和高速NOA功能;PRO、AIR车型搭载的都是”AD PRO“智驾,具备高速NOA功能。
从这次的发布会的重点来看,只是针对AD MAX方案的优化。
而且直接和众多友商看齐:全国都能开,不论城市主干道、小道还是乡间,能导航的地方都可以使用。
在发布会上,理想汽车还展示了一张在全国范围内,在18点到20点这两个小时之间使用无图 NOA的用户数据,根据他们的位置,形成了一张轨迹图,以此来佐证理想汽车的无图NOA真正具备了全国都能开的能力。
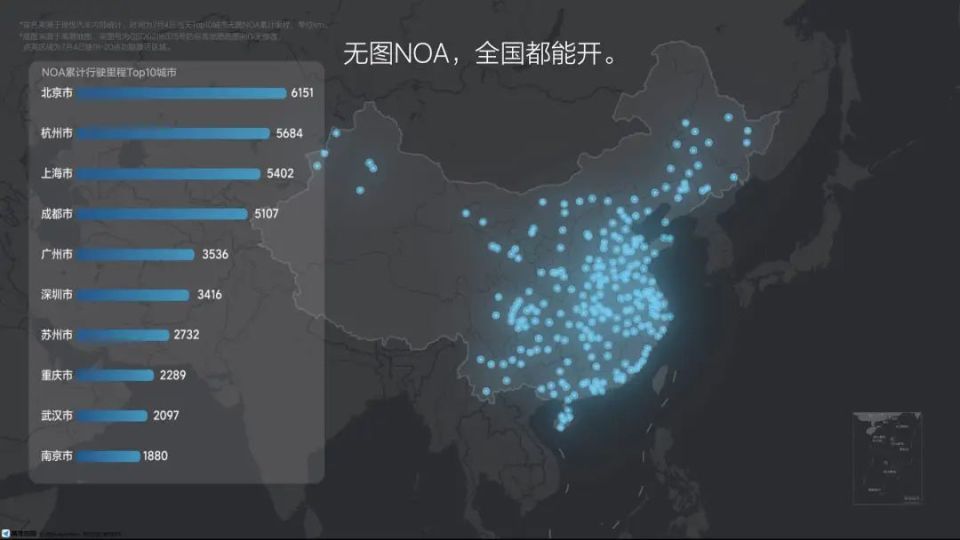
最新的无图NOA相比过去的版本,BEV、感知能力、规控能力,还有整体系统能力得到全面提升,特别是将纯视觉的OCC占用网络升级为Lidar与视觉前融合的占用网络,具备分米级的微操能力,从而精准识别更大范围内的不规则障碍物,感知精度更高。

做到“全国都能开”,是因为无图的概念就代表着不再依赖高精地图或先验信息,在以往的智驾决策中理想打了个比方,就像背后很多“小机器人”在运行,可能有一些“小机器人”需要一些先验信息,也就是需要导航数据的先验信息进行决策。
而通过运用BEV算法的感知能力进行一系列技术复合决策,并将摄像头拼接的周边环境、道路信息、导航提供的轨迹和数据信息全部合并在一起,形成超视距能力,在行驶的过程中就可以生成最优路线,不再过多依赖“先验”信息。
另外,新系统采用了全新的时空规划算法,使整体决策变得果断,从而表现出第二个特点———绕行能力强。
绕行能力是评价城市 NOA 的一个重要指标,因为其在实际驾驶中应用的场景非常频繁,比如遇到动静态的障碍物,优秀的绕行能力可以巧妙化解,绕行能力弱就只能陷入无尽的等待,甚至接管。

这里理想汽车衍生出了时间和空间的概念,通过横纵(前后左右)同步规划,能够持续预测自车与他车的空间交互关系,并规划出“未来一段时间窗口内”的所有可行驶的轨迹,筛选出最优最高效的轨迹。
这样一来,即便是在复杂路口也能轻松通过,仿佛拥有了“上帝视角”,也是其另一个特点——路口轻松过。
搞定“高频低危”
理想汽车表示,今年上半年,理想汽车人类驾驶的事故率降低了30%,期间理想 AD Max 主动安全系统共为用户规避了36万起潜在事故,且AEB误触发率降低到小于 30万公里。
而且对于道路上的潜在威胁,理想汽车做了一个「安全风险场景库」,按照从低危到高危、从低频到高频的顺序排开,把风险场景分成了 9 种类型。

理想汽车高级副总裁范皓宇表示,去年推送的 OTA 5.0 已经能够应付「低频高危」和「中频中危」这两个部分的威胁。
如今推送的OTA 6.0 就是要提升车辆在高频低危场景下的能力。
比如在经过复杂路口,理想汽车的AEB(自动紧急制动)系统能够全面覆盖行人、两轮车和三轮车等典型障碍物,无论它们从左、右或前方靠近,系统都能及时响应。

而且系统内设计了安全阈值,一旦有障碍物侵占了理想汽车的安全系统区间,都会启动AEB帮助用户主动刹停。如果出现了在盲区的车辆,自己的车辆侵占了对方的安全性空间,同样会主动刹停。
另外就是高速上的夜间行驶,周围基本上没有光照的情况下,夜间AEB尤为关键。如果前方不远处有一辆货柜车停着静止不动,没有开灯、没有反光条,这样的场景下,AD Max的AEB能做到120公里时速完全刹停。
理想汽车还提供了全自动AES(自动紧急转向)功能,以应对“消失的前车”这种极端场景。
比如说,以非常快的速度在高速上行驶时,突然前车急刹停或者避让,因为距离太近无法及时停下时,这种情况下AES(自动紧急转向)就会介入,车辆会减速并执行避让功能,进一步提升了安全的上限。
最后,还提供了全方位低速AEB(自动紧急制动),主要针对泊车和低速行车场景。

在日常的高频低速场景中,特别在地库停车环境复杂的情况下,可能会出现比如柱子、墩子或者低速的行人增加剐蹭风险,全方位低速AEB就能识别来自前向、后向和侧向的碰撞风险,及时紧急制动。
当然,从安全性的功能上看,可以说是全方位无死角的保护,但是在实际应用中出现误报和误刹也是一个不小的困扰,这一点仍需要后续的实际体验。
双系统支持
除了7月内推送无图 NOA,理想汽车还在发布会的后半程提出来一个灵魂拷问:真正实现自动驾驶的技术方案是什么样的?
理想给出的答案,也是端到端大模型,不过理想认为如果面对中国复杂路况,只有端到端不够。
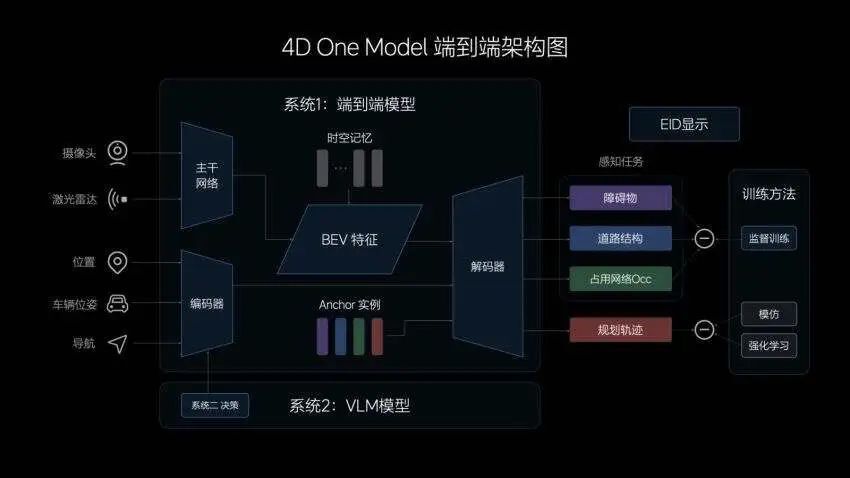
基于此,理想提出来一个全新的方案:E2E(端到端大模型)+VLM(视觉语言模型)。
有意思的是,这个方案的灵感还是来源于认知心理学的原理,诺贝尔奖获得者丹尼尔·卡尼曼在《思考,快与慢》中,使用系统 1 和系统 2 的理论来解释了人类决策和思考的过程。
系统1是人根据自己过去的经验和习惯形成的直觉,可以做出快速的决策,比如“1+1=2”的问题系统2就是一个思维推理能力,人需要经过思考或推理才能解决这种复杂的问题和应对未知的场景。
简言之,系统1和系统2相互配合,构成了人类认知和理解世界、做出决策的基础。
那么,系统1和系统2是如何类比到自动驾驶中的?很简单,端到端是系统一,作为主决策者,VLM视觉语言模型,当作系统2,可以理解为系统1的“冗余”。

这么理解就简单了,运用端到端技术处理泛化的场景,而VLM视觉语言模型作为系统2,则具备一些逻辑思考的能力,会在一些复杂情况下验证“端到端”的决策,最终实现车辆的兜底或控制。
按照理想汽车智能驾驶技术研发负责人贾鹏的说法,人开车的时候其实都是系统1在工作,可能只有 5%的情况,会使用系统 2。
理想汽车也表示,届时会有两颗Orin-X分别负责系统一和系统二。
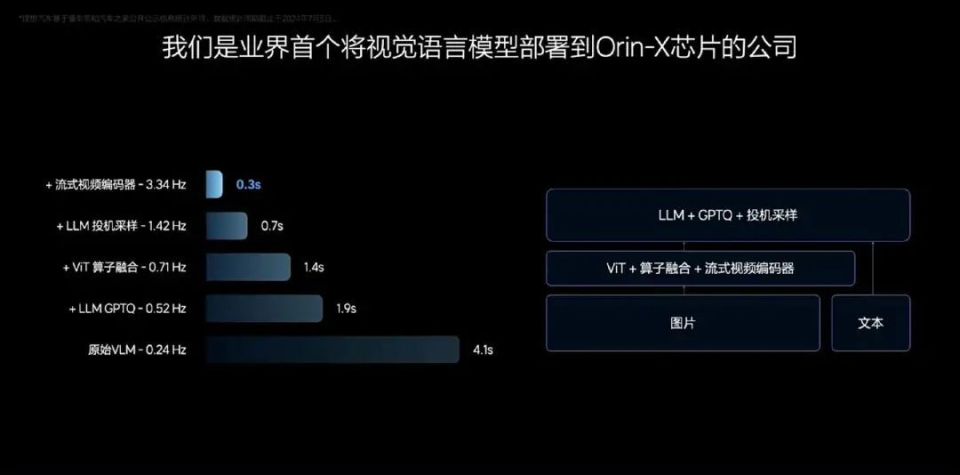
如今端到端大家都知道是怎么回事,但理想提出的VLM视觉语言模型还很新鲜的。
VLM视觉语言模型可以看做是一个统一的Transformer模型,参数量能达到22亿,Prompt(提示词)文本进行Tokenizer(分词器)编码,并将前视相机的图像和导航地图信息进行视觉信息编码,再通过图文对齐模块进行模态对齐,最终统一进行自回归推理,输出对环境的理解、驾驶决策和驾驶轨迹,传递给系统1辅助控制车辆。
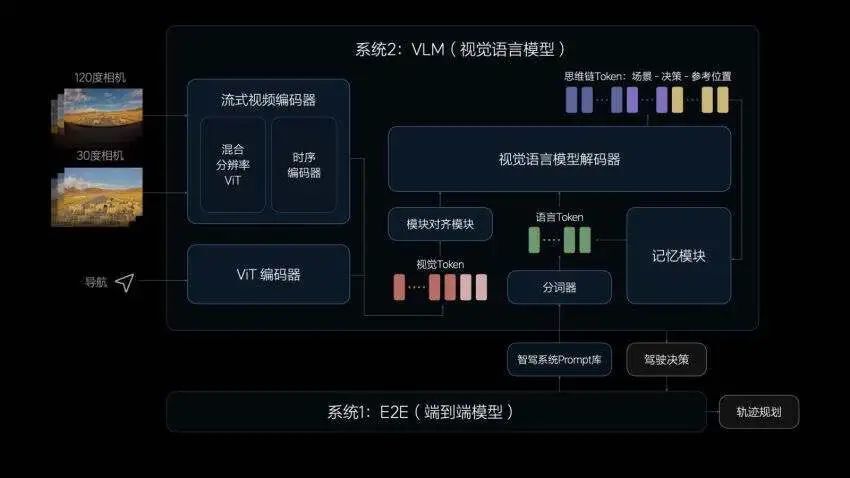
通俗点说,其具备强大的理解能力,识别路面平整度、光线等环境信息,同时,VLM模型还具备更强的导航地图理解能力,可以修正导航,预防驾驶时走错路线。
不过如今这套系统还没能上车验证,但理想为了验证这些技术的有效性,他们使用Diffusion Transform在模拟环境中构建小型世界模型,让车辆在其中进行测试。
理想称其为自动驾驶系统考试方案,其中包括“重建+生成”。
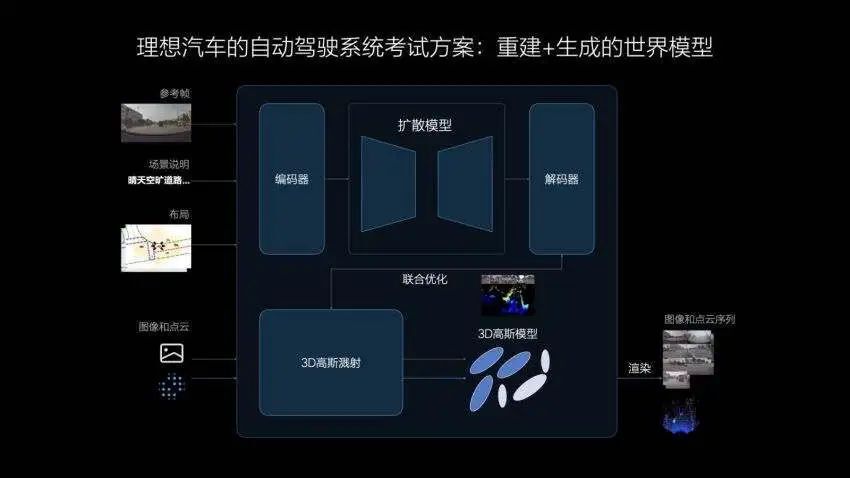
理想先是通过3DGS(3D高斯溅射)技术对真实数据进行场景重建,然后利用生成模型补充新的视角,从而创建出既符合真实世界场景又能解决新视角模糊问题的环境。
在场景重建时,其中的动静态要素将被分离,静态环境得到重建,动态物体则进行重建和新视角生成。再经过对场景的重新渲染,形成3D的物理世界,其中的动态资产可以被任意编辑和调整,实现场景的部分泛化。

生成模型相较于重建模型具有更好的泛化性。理想能够自定义改变天气、时间、车流等条件,生成多样化的场景用于评价自动驾驶系统在各种条件下的适应能力,通过这种无限环境,理想可以对自动驾驶系统进行充分的学习和测试。
虽然尚未得到验证,但也不远了,理想汽车在发布会上透露,端到端+VLM大模型也即将开始内测,尽早让用户进行早鸟体验。

























