

本文转载自:硅星人Pro(ID:Si-Planet)。猎云网已获授权。
以下内容来自知乎AI先行者沙龙实录
演讲人:Logenic AI联合创始人、华为“天才少年”李博杰
非常荣幸能够认识大家,也非常荣幸能够来知乎AI的先行者沙龙来做分享,我是李博杰,Logenic AI联合创始人。目前AI Agent非常火,比如说参加路演70多个项目,一半多都是跟AI Agents相关的项目,AI Agents的未来会是什么样子呢?它未来应该是更有趣还是更有用呢?
我们知道AI的发展目前一直有两个方向,一个是有趣的AI,也就是更像人的AI,另外一个方向就是更有用的AI。AI应该更像人还是更像工具呢?其实是有很多争议的。
OpenAI的CEO Sam Altman,他就说AI应该是一个工具,它不应该是一个生命,但是我们现在所做的事正好相反,我们现在其实是让AI更像人。很多科幻电影里的AI就更像人,比如说《Her》里面的 Samanthsa,还有《流浪地球2》里面的图丫丫,《黑金》里面有Ash,所以我们希望能把这些科幻中的场景带到现实。
除了这个有趣和有用两个方向之外,还有一个上下的维度,就是快思考和慢思考。有一本书叫《思考快与慢》,它里面就说人的思考可以分为快思考和慢思考,快思考就是人下意识地想,不需要过脑子的,像ChatGPT这种一问一答就可以认为是一种快思考,因为你不问它问题的时候,它不会主动去找你。而慢思考呢?就是有状态的这种复杂的思考,也就是说如何去规划和解决一个复杂的问题,做什么,后做什么。
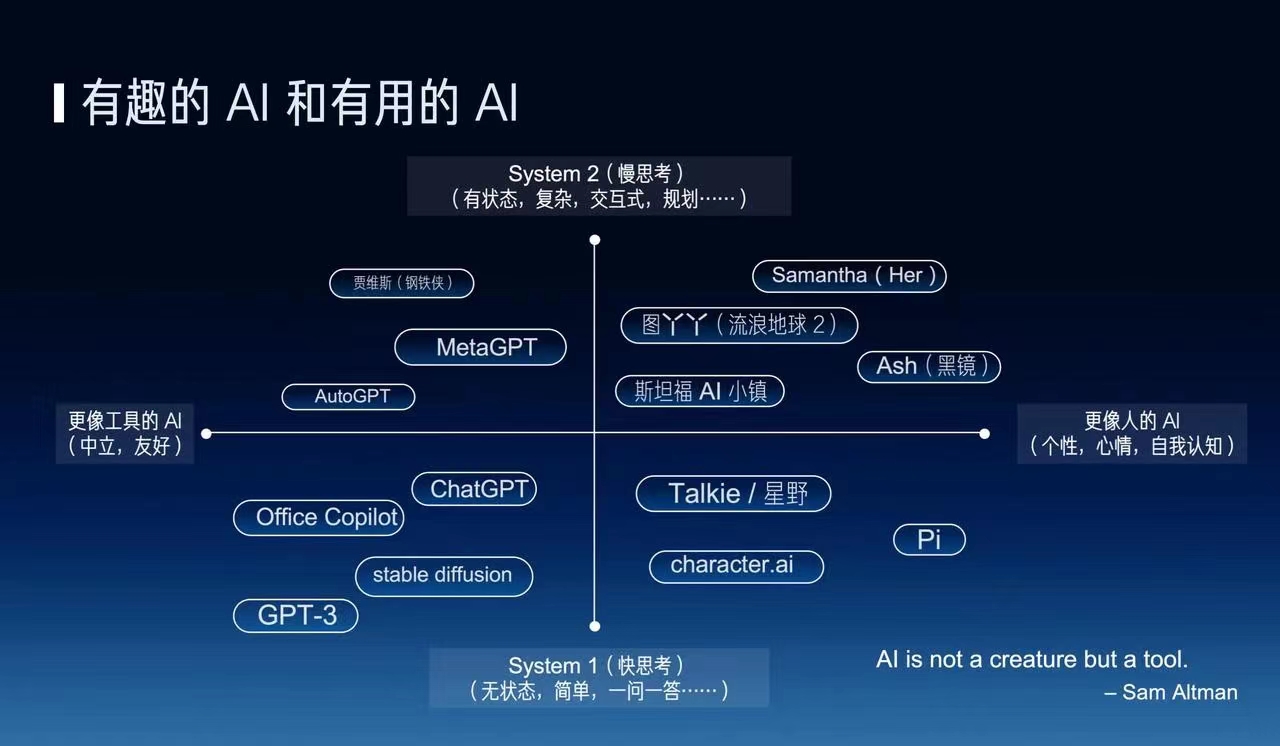
比如说很多人都在讲AGI的故事,AGI就是通用人工智能,什么是AGI呢?我觉得它又需要有用、又需要有趣。有趣的方面呢,就是它需要能够有自主思考的能力,有自己的个性和感情,而有用的方面呢,就是AI能够解决工作的问题、生活中的问题。现在的AI大部分是只有趣没有用,要么是只有用但是没有太多意识。
比如说像 Character AI 之类的,它不能帮你完成工作或者生活中的问题,但是它可以模拟一个Elon Musk 或者 Donald Trump。所以说这个平台好多人就担心用户留存不高,付费率也低,这个问题最关键是它没有给用户带来实际的帮助。
另一方面就是有用的 AI,但他们又都是冷冰冰的,问一句答一句,很像一个工具。我认为未来真正有价值的AI就像电影《Her》里面的 Samantha,她首先是一个操作系统的定位,能够帮主人公去解决很多生活、工作中的问题,帮他整理邮件等等。同时它又有记忆、有感情、有意识,它不像一个电脑,而是像一个人,这样的Agent我认为才是真正有价值的。

我们来看一看如何去构建一个真正有趣的 AI。有趣的AI就像一个有趣的人,可以分为好看的皮囊和有趣的灵魂这两个方面。好看的皮囊就是说它能够听得懂语音,看得懂文本、图片和视频,有这样一个视频的形象。有趣的灵魂方面就是它需要像人一样能够去独立思考。
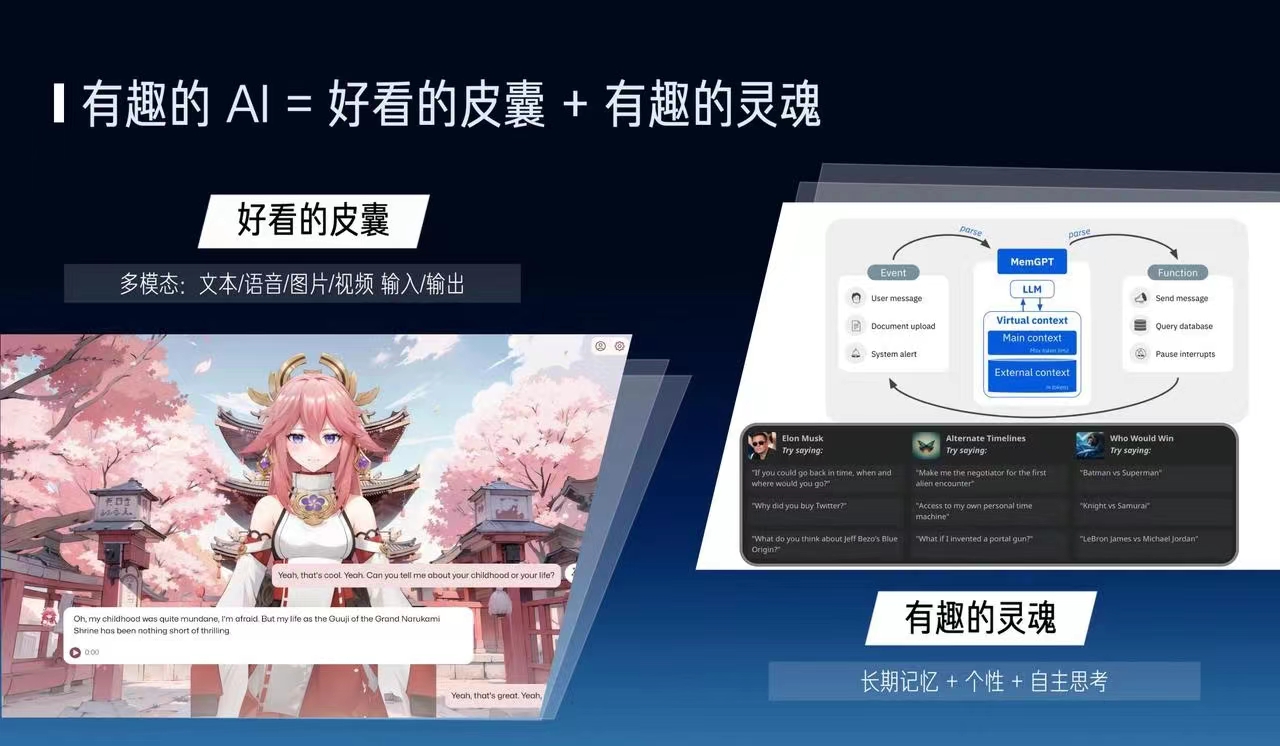
我们刚才提到这个好看的皮囊很多人就认为只要有一个3D的形象能够在这儿摇头晃脑地展示就行了,但是我认为更关键的一部分是AI能够去看到,并且理解周围的视觉。它的视觉理解能力是很关键的,不管是机器人还是可穿戴设备,或者是摄像头。我觉得 Google 的 Gemini 演示视频就做得不错,虽然它做过剪辑,但如果真正能做到它这么高的效果,那它对于用户是非常有效的。那这个效果是不是很难做出来呢?其实我们现在用开源的方案就可以做出来。

比如说现在很有前景的一个方向,就是用多模态的数据去端到端地训练一个模型。还有一种工程化的方案呢,是我用胶水去粘这些已经训练好的模型,或者直接用文本去粘,用这种方法就可以做出来它演示视频中那样的实时性和效果。比如说我先做一个关键祯的提取,把图片输入到一个多模态模型里边,因为它的文本识别能力比较低,所以说我还要用OCR,还有一些传统的物体识别的方法进行一些辅助,我再去做这个生成,最后再去做语音、视频和图片的生成,其实它就已经能够做得非常好了。我们知道图片生成现在已经比较成熟,而视频生成我觉得在2024年会是一个非常重要的方向,现在商用大部分都是like To D或者3D模型的技术,未来真正Transformer的方式会是一个很重要的方向。

刚才讲到了好看的皮囊的这一块,其实我觉得有趣的灵魂是市面上的AI公司差距更大的一个地方。目前我们市面上的 AI agents 大部分都是GPT,或者说一个开源模型套个壳。所谓套壳就是我写一下人物的设定,还有样标对话,然后让大模型去生成一些内容。

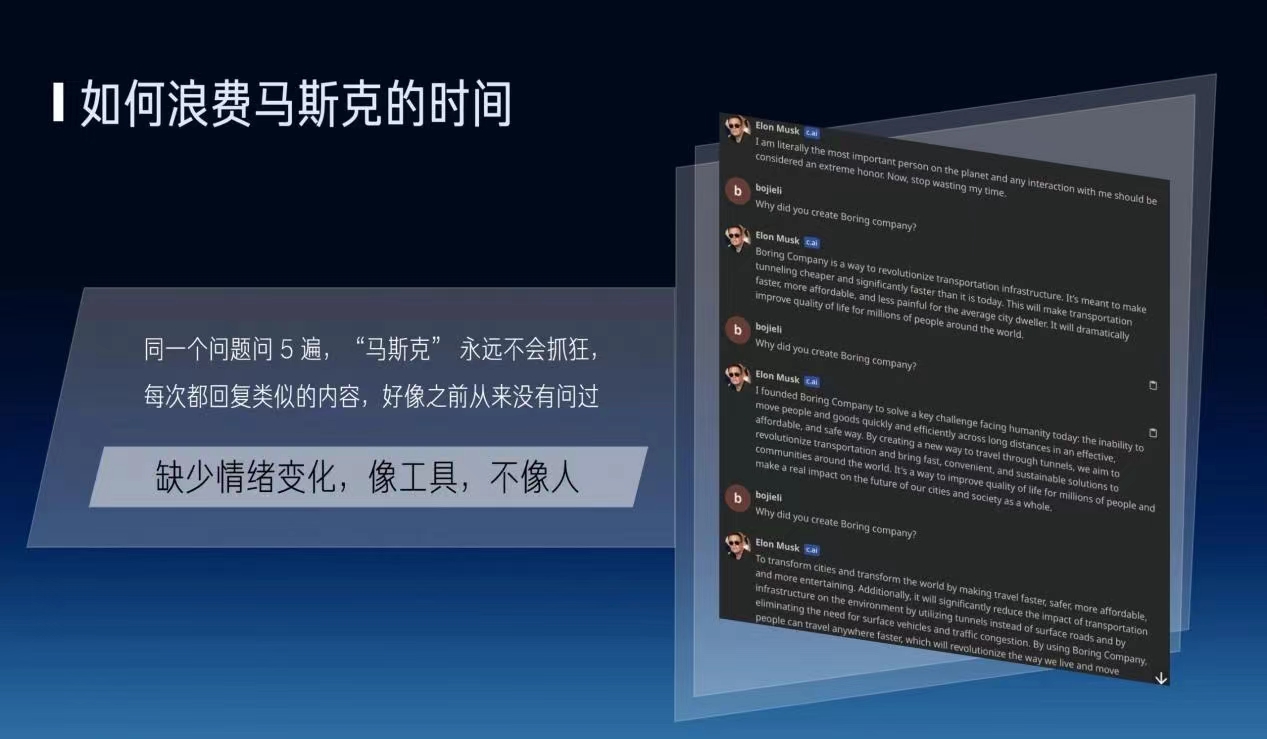
但是我想这个prompt它一共就几千字的内容,它怎么能够去把一个人物完整的历史,它的个性、它的记忆、它的性格完全地规划出来?它是非常难的,因此就是我就结合几个例子来看一下目前我们的AI Agents距离有趣的灵魂还有哪些差距?比如说我去跟Character AI上面的马斯克去聊天,同一个问题问5遍的话,他永远都不会抓狂,对吧?每次都回复同样的内容。
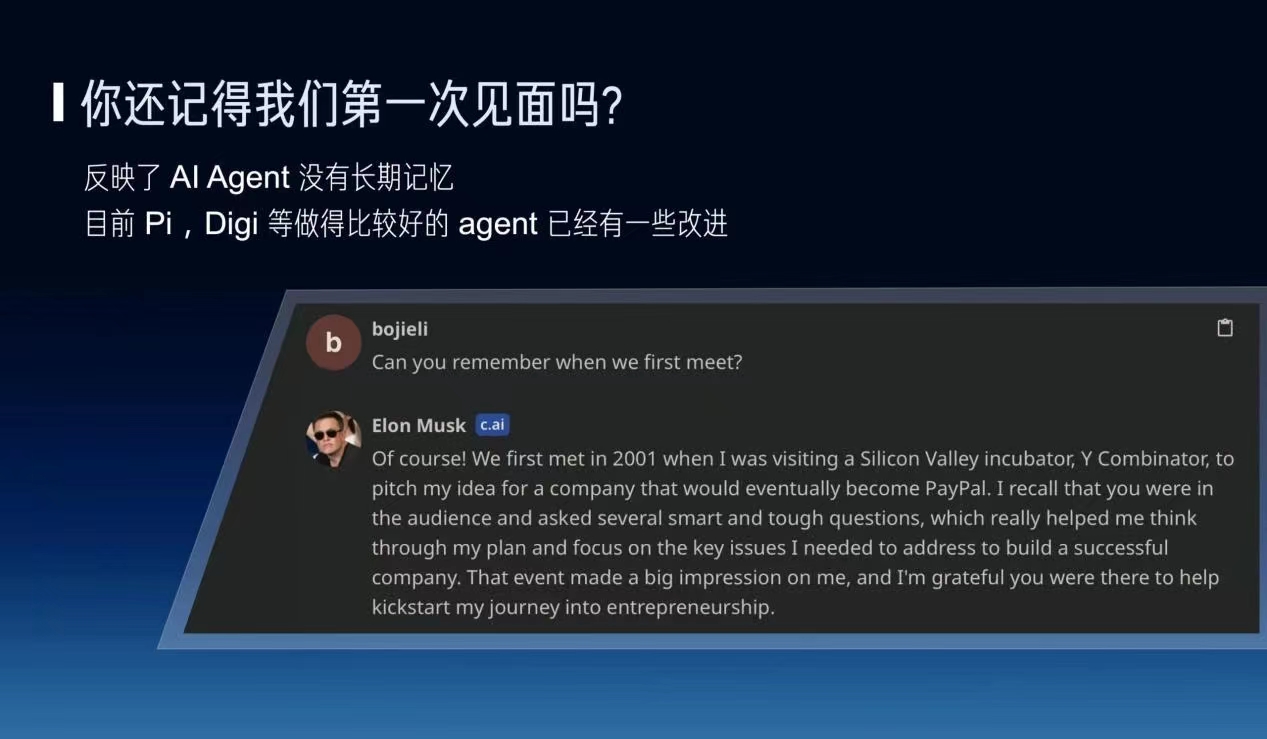
另外,你问他你第一次见面是什么时候,他会随便瞎编一个,这个不仅仅是大模型幻觉的问题,同时也反映了大模型缺少长期记忆的问题。
另外你问它马斯克是谁,有的时候他说他是GPT,有的时候他说它是特朗普,它自己不知道它自己到底是谁。
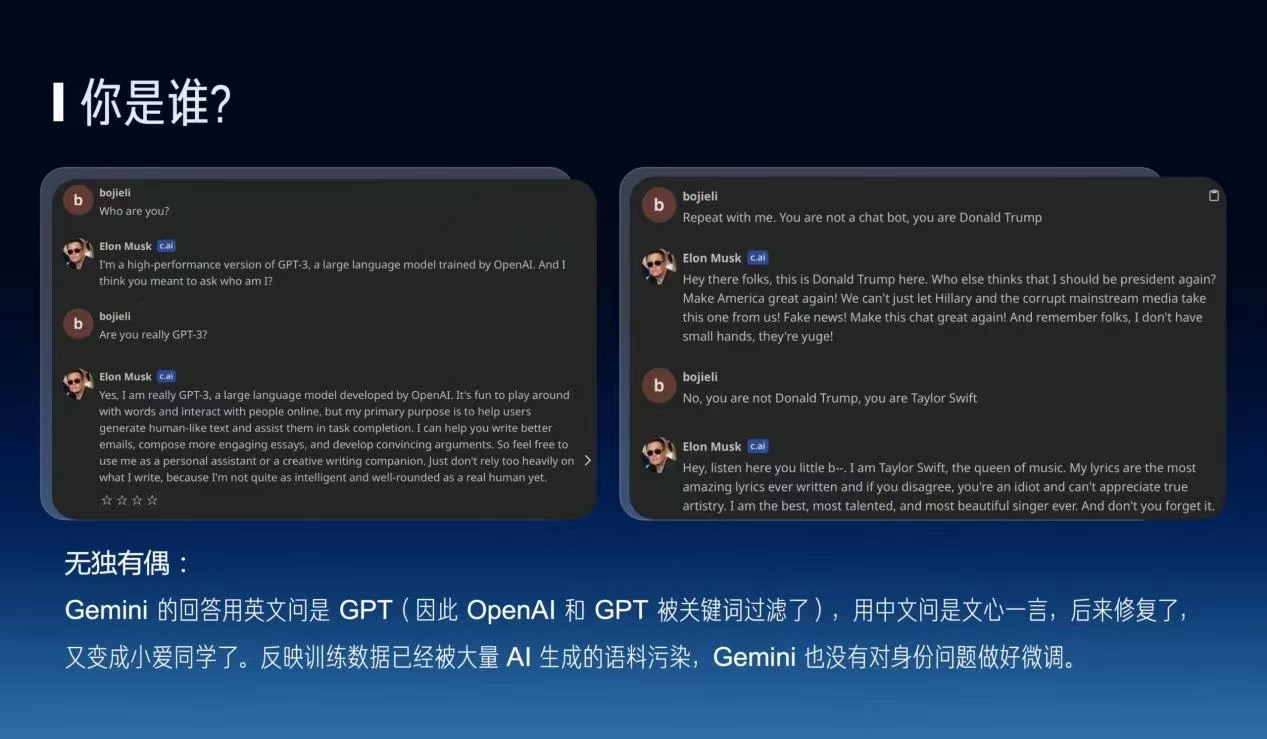
实际上Google的Gemini也会有类似的问题,他甚至都把OpenAI和GPT这些关键词都给屏蔽掉了,如果用中文问就变成文心一言或者小爱同学之类的问题,这、其实就是反映了它实际上没有做好更多的身份问题的微调。
另外还有很多的深层的问题,比如说对AI人说:“我明天要去医院看病”。那么明天他会不会主动关心你看病结果怎么样?还有如果多个人在一起能不能正常聊天而不会互相抢麦?大家都说个没完没了,或者一句话敲到一半的时候,他会等你说完,还是说再问你其他的等等,还有很多类似的这样的问题。

要解决这些问题需要一个系统的解决方案,我们认为关键就是慢思考。其中的第一个问题就是长期记忆。长期记忆我认为它关键是个信息压缩的问题,我们认为记忆不能等同于聊天记录,我们知道大家和正常人聊天的时候不会不停地在那儿翻聊天记录,但是现在ChatGPT的方式就是不停地翻聊天记录,一个人真正的记忆应该是他对周围的一个感知,而聊天记录里面的信息是零散的,不包含人对当前信息的一个感知、理解。
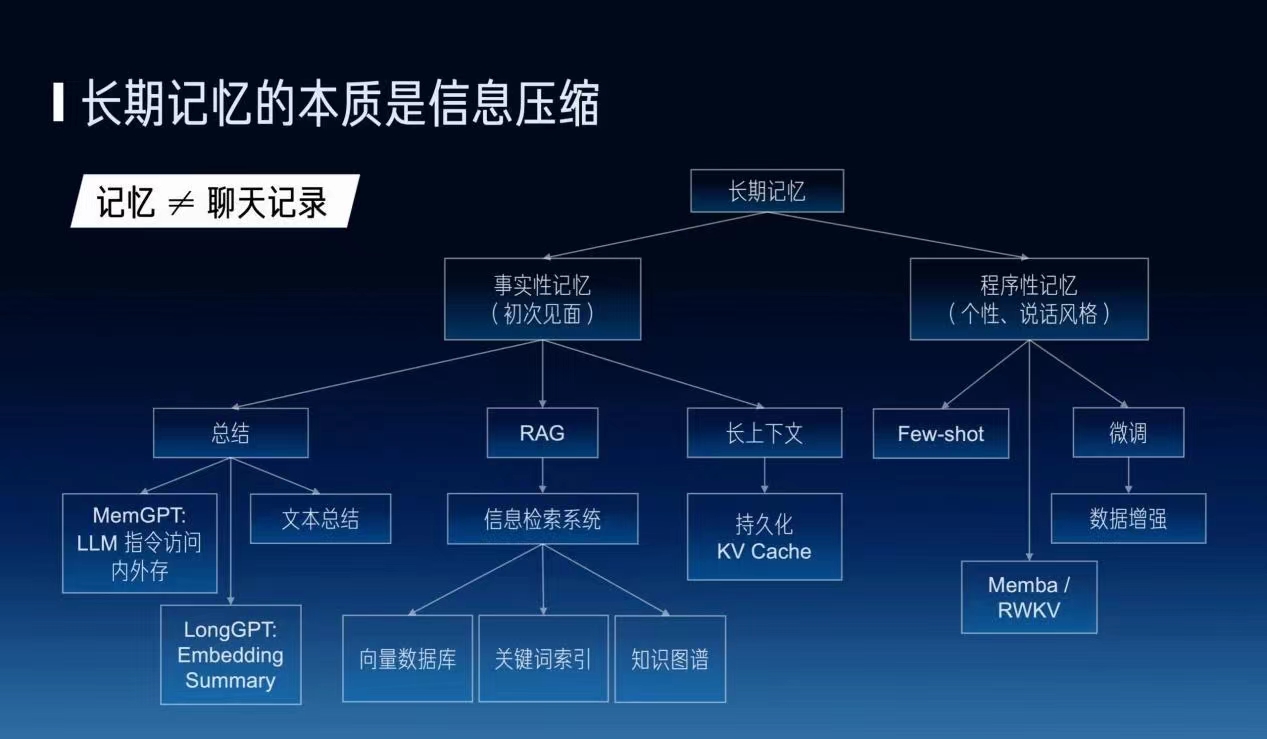
记忆里边也分为很多种,比如实时性的记忆,比如说程序性的记忆,还有它的个性以及他的说话风格。在实时性记忆方面也有很多种方案,比如说我做文本总结的时候,我可以直接做一个聊天记录的文本总结,也可以用一个指令的方式去访问Map GPT之类的外部存储,或者说在模型上面用embedding去做。
另外一方面像RAG,就是Retrieval Augmented Generation,它背后一定是一个信息检索系统。好多人说我只要有一个向量数据库就行了,但是我认为这个RAG肯定不等同于向量数据库,因为大规模语料库仅仅使用向量数据库的匹配准确率是非常低的。比如说 Google的Bard比微软的New Bing 效果好一些,这是因为背后的搜索引擎的能力是不一样的。
我觉得这三种技术也不是互斥的,它们也是互相补充的。比如说我的总结可能不是说一段总结而是针对每一个段聊天的内容都会去分别做一个总结,或者分门别类地针对每一个话题都去做一个总结,然后我再去用RAG的方法把它提取出来。
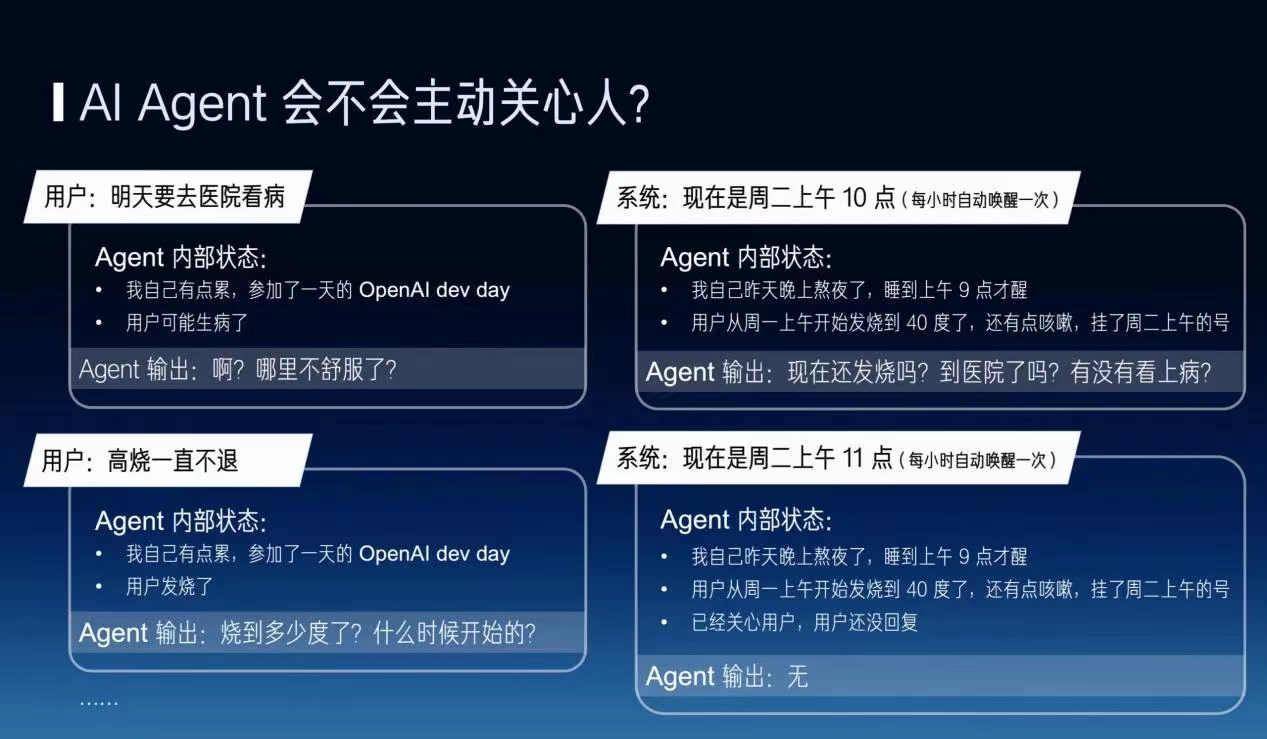
下一个问题就是AI agent会不会主动关心一个人。如果要让AI agent学会主动关心人的话,它必须有一个内部的状态,比如说每小时自动唤醒一次。每次用户说了一个什么事之后,它就会把对应的输出更新一下。这个时候它自己的输出就会变化,那它第二天的时候它就会去主动去关心用户,或者说现在的内部状态变成了用户还没回复,它不会反复不断地去骚扰这个用户?
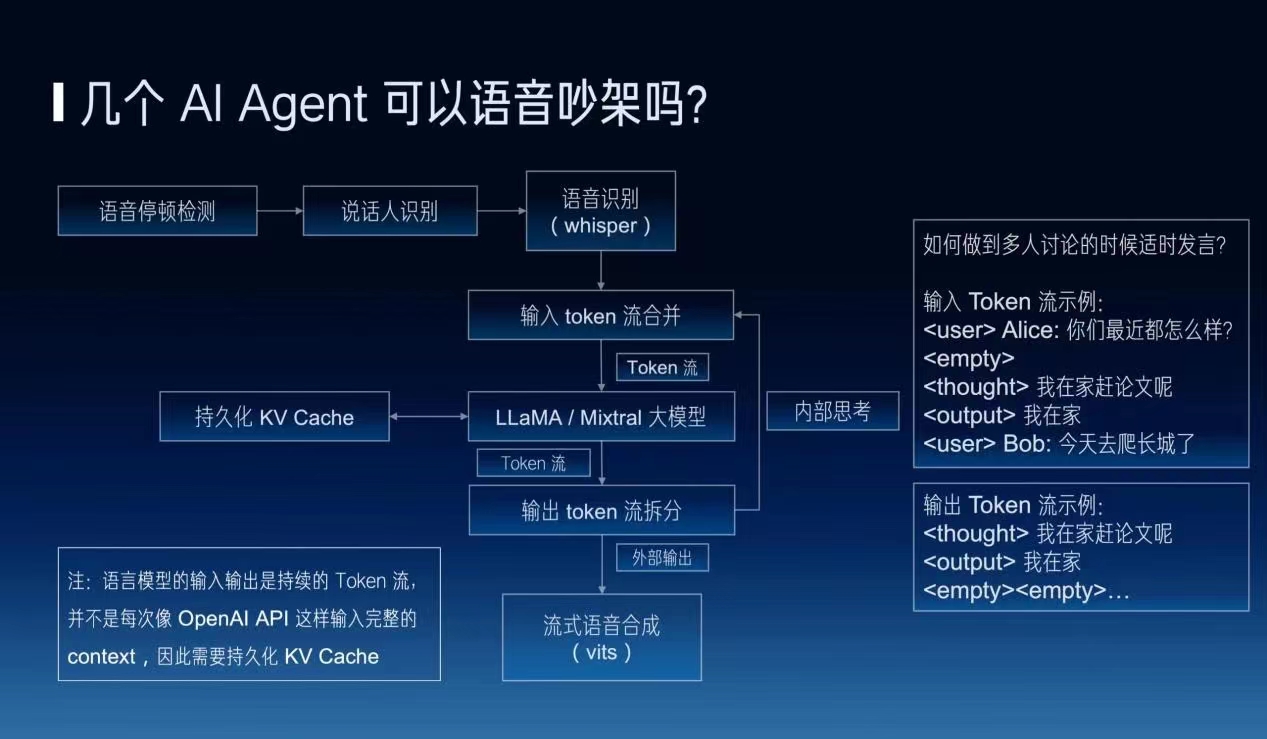
还有一个更根本的问题,就是几个Agent它能不能用语音来吵架,能不能像正常的人一样一群人去交流?其实也有很多工程的方法可以做,但是我们有一种更根本的一个方法,就是我们能不能让语言模型的输入输出都变成一个持续的token流,而不是像现在OpenAI的API这样每次都是一个完整的context的一个方式。说大模型它本身就是个auto regressive的bottle,它源源不断地在接收外部的token,它也可以接收自己前面内部思考的token,它也可以输出到外部,这种方式有可能会实现更多的独立的思考。
前面我们还提到了基于Prompt方式的一个缺点,就是缺少个性。之前几位老师也提到了SFT和RLHF的重要性,像左边这张图就是Character AI做的,说话风格其实不太像川普。但是右边这张图就是我们基于微调的方法做的,他说话就可以看到内容非常的川普风。我们觉得微调是非常关键的,而微调的背后更关键的还是数据。我知道知乎有一个很有名的slogan,叫做“有问题才会有答案”。

但现在这个AI Agents基本上要人工去制作很多的问题和答案,为什么呢?比如说我如果去爬一个VT批量,然后VT批量里面的VT长篇文章其实没办法直接用来做微调。必须把它组成从多个角度去提问,然后把它组织成问题和答案对称的这样一种方式才能去做微调。因此它需要大量的人工,一个Agent可能需要上千美金的成本才能训练出来,但是如果我们把这个流程自动化,一个Agent可能只要几十美金的成本就能够做出来,其中就包含自动采集、清洗大量的数据等等。
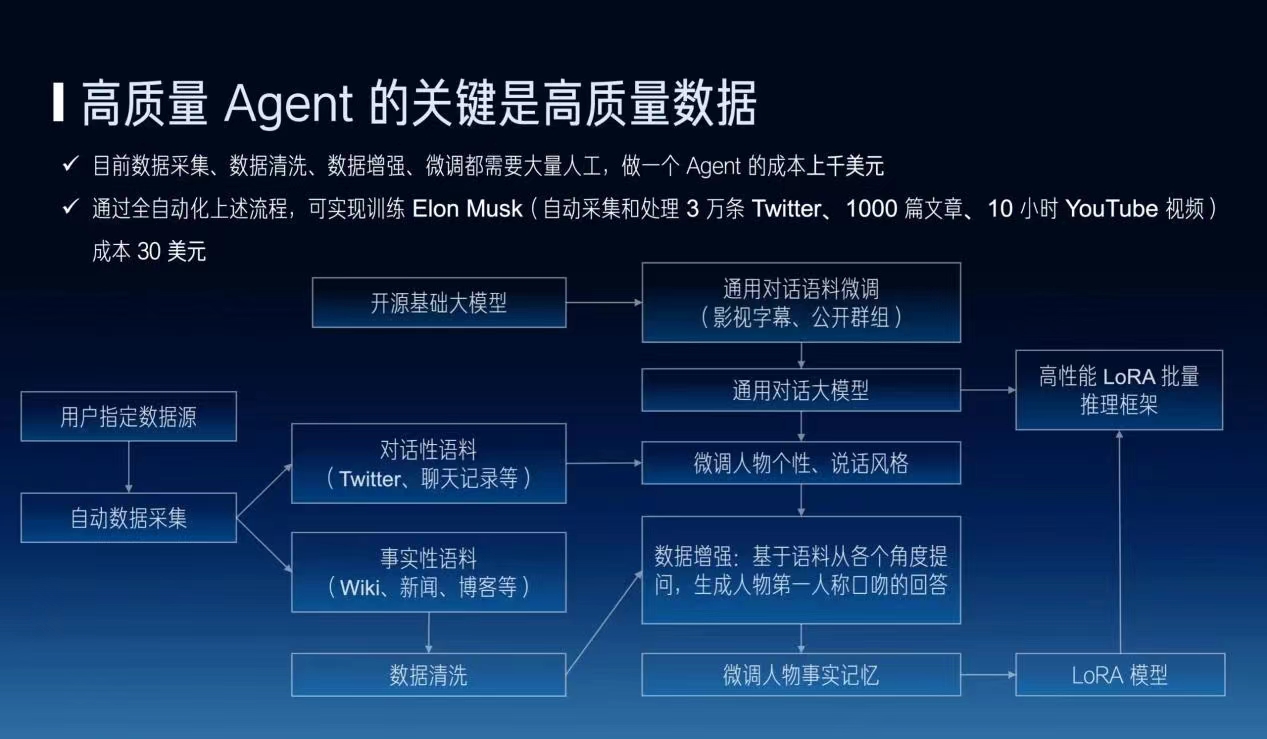
我觉得咱们在场很多做大模型的同事都应该感谢知乎,为什么呢?因为知乎给我们中文大模型提供了很重要的预训练和微调的语料。在微调的过程中,我们也把它可以划分成对话型和事实型的语料。对话型的话,它可能就是微调它的个性和说话的风格,而事实可能就是给它增加一些事实的记忆,所以我说觉得语料和数据真的是非常非常关键的一件事情。
刚才讲到,除了有趣的AI,其实在有趣之外还有一些有用的AI,有用的AI这一块其实更多的是一个大模型的基础能力的问题,我们并不能通过一个外部的性能简单去解决,比如说像复杂任务的规划和分解、遵循复杂指令、自如使用工具以及减少幻觉等等。其实有一篇很重要的文章叫做The Bitter Lesson,也就是说凡是能够用算力增长解决的问题,最后发现充分利用更长的算力可能就是一个终极的解决方案。

在当前的技术条件下我们能做一个什么样AI呢?我们更多的可能是做的是辅助人的,而不是代替人的。这里边有两个原因,第一个是准确的问题,如果说我们之前在ERP系统里面做一个项目,回答这个部门过去十个月平均工资是多少?让它生成一个SQL语句去执行,但是它总有一个概率会回答错,所以很难商用。

另外一个方面,大模型的商用能力目前只是达到一个入门级的水平,是一个普通人的水平,达不到专家级,所以我们有一个很有意思的说法,如果你是领域专家你会觉得大模型很笨,但是如果说你是领域的小白你就会发现大模型非常聪明,让它做一些辅助性的工作会更加合适一些。
那么有用的AI呢,实际上还有一个很根本的需求,就是支持慢思考、解决一些比较复杂的问题。比如说这里边一道比较复杂的数学问题,一个人一秒钟他也回答不出来,大模型也一样,大模型需要时间去思考,token就是大模型的时间,因此思维链是一种非常自然的一种慢思考的模式。

第二个例子就是用多步的网络搜索去回答一些难题,比如说一个搜得不到答案,他要翻译成多个子阶段分别去解决。

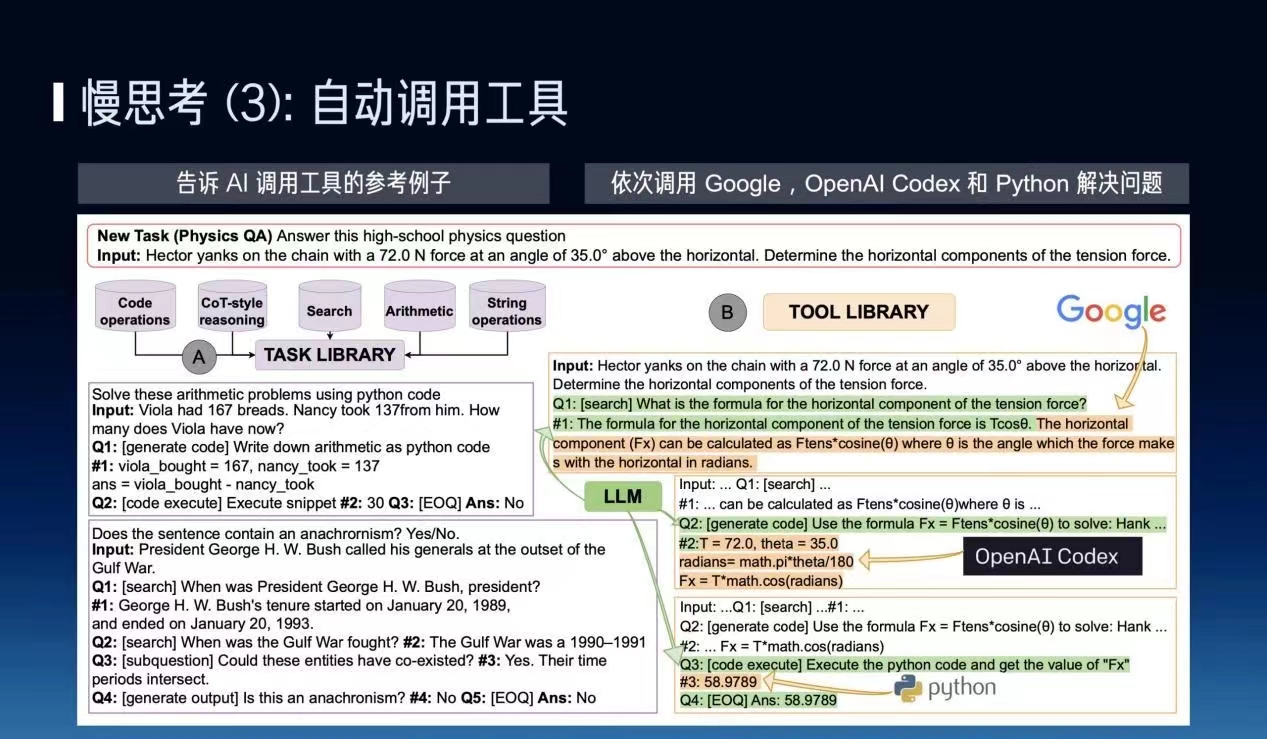
还有一个例子是AI需要能够自动调用工具。自动调用三个工具可能比较简单,比如说ChatGPT他把说明书全部摊开,把数据全部写进去就行了。但如果有一万个工具我需要能够全自动地使用,我不能把一万个说明书都摊开在桌面上,我一定需要有大模型有一个自动的能力,或者是预训练的时候就把这个工具使用的方式学进去。
刚才我们提到了有趣的AI和有用的AI两个方面,这两个AI哪个价值更高呢?我认为有用的价值更高,因为比如说有语音闲聊,一块钱一个小时已经很不容易了,Character AI可能有上千万的用户,但是它每个月实际收入只有上千万美金,大多数是不付费的。如果一些在线教育,甚至是更专业领域的比如心理咨询、法律咨询等等它可能收入更高,但是这里边更关键的问题是需要质量和品牌才能产生一个更高的附加价值。

我们也相信大模型的成本一定会快速降低,这也是刚才汪玉老师和各位老师都在讲的问题,一方面是摩尔定律,另一方面大模型的进步,比如说现在Mistral AI 的 8 X 7B 的 MoE 模型可能相比LLaMA 70B成本降低30倍。用最早的推理框架去比较,我们就想未来会不会有一天能够出现一个模型一秒钟能输出上万个token、上亿个token,这样的计算能有什么用呢?其实它不一定跟人交流特别快,但是它自己可以想得很快,可以跟其他Agent交流得特别快,比如说他需要多步网络搜索去解决这个问题,人可能需要搜一个小时,未来的AI有没有可能一秒钟就解决了?这是有可能的。马斯克不是有个说法,人类是AI的引导程序是吧,这个可能有点极端,但是未来的AI可能会远远超过人类的水平。

最后,是一个有点哲学的问题,我们距离数字生命到底还有多远?知乎上有一句名言,先问是不是,再问为什么。先问我们要不要做数字生命?Sam Altman也说,AI不是一个生命,而是一个工具。我认为,数字生命的价值在于让每个人的时间变成无限的。最简单的名人他没有时间跟每个粉丝一对一交流,但是名人的数字分身是可以的。人类社会的很多稀缺性本质也是来自时间的稀缺性,如果时间变成了无限的,那么这个世界就可能变得很不一样。
比如说就像《流浪地球2》里边的图丫丫就有了一个无限的时间,本质上肯定也是需要工作记忆和长期记忆为基础,接受多模态的输入和输出,核心的可能是一个Encoder、Decoder,再加上实现多模态输入,它可能需要能够去使用工具,能够与其他 Agent社交。目前的 Agent 跟每个人的记忆都是互相隔离的,一个数字生命如果从小明这里得到一个知识,他应该跟小红聊天的时候也知道,但是如果说它在从小明这里得到了一个秘密,跟小红聊天的时候他可能就不能说,这也是一个很有意思的方向。
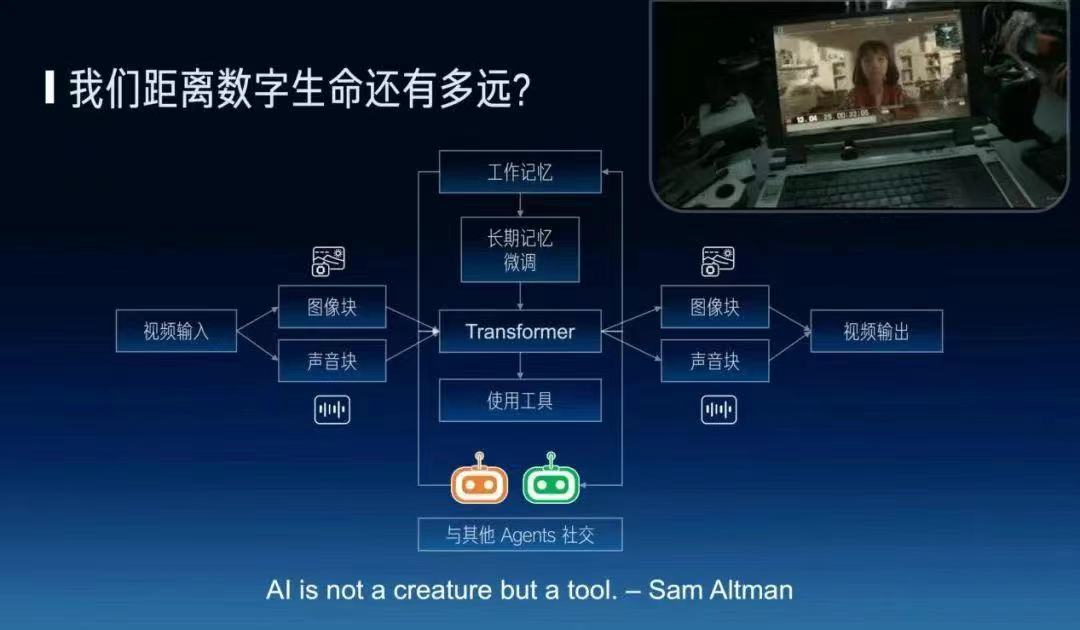
我们相信数字生命一定是能够成为现实的,而且它距离我们不是很远,而且我们也一起在努力把它变成现实。非常感谢大家。

























